User viewport prediction for live VR video streaming system
Given the demands of high resolution and high frame rate in VR streaming to ensure user’s quality of experience (QoE), the VR video content is typically huge in size and thus poses significant challenges in the network bandwidth consumption. Even if a single or small number of VR video viewing sessions can be supported by the state-of-the-art high bandwidth networks, the nature of the video streaming services that could involve millions of concurrent viewing sessions would create significant capacity challenges in both the backbone and edge networks. Such challenges would eventually be converted to degraded QoE towards the user end, significantly blocking the wider deployment of premium VR experiences.
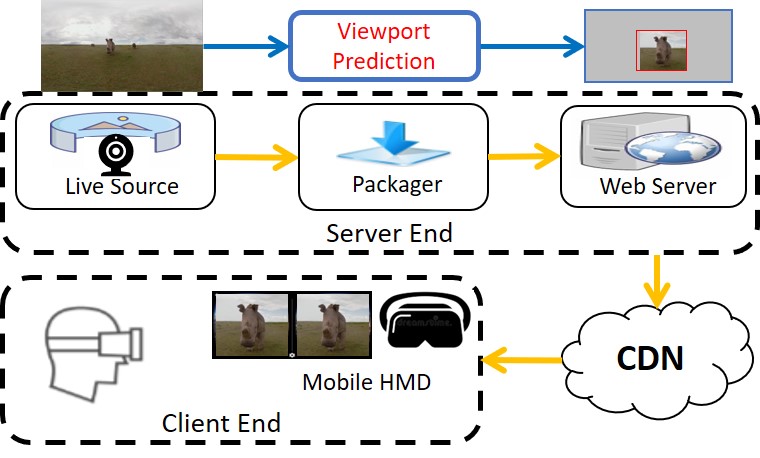
The potential solution to the bandwidth challenge of VR streaming leverages the fact that the user can only watch an around 90- degree viewport at any point of time, leaving the rest (more than 80%) of the video content in the 360-degree frame unnecessary to be delivered to the mobile HMD. One example solution is selective streaming [38], which proposes to stream the portion of video that the user is more likely to watch in high resolution, while the rest of the video is delivered in low resolution.
Solution A: Motion detection and feature tracking(LiveMotion)

We develop a new viewport prediction scheme that works with live 360 video streaming and complicated user head movement patterns. Different from all the existing approaches on the historical or current user behavior, our approach employs a user model combining the video content and the user interests for viewport prediction. Our key idea is that, even though the user behavior is hardly predictable, there is often a close correlation between the user’s viewport of interest and the moving objects in the video. It is because most users would focus and follow the most active objects in the 360-degree frames, which are often the objects in motion (e.g., the ball in a soccer game). Therefore, we employ computer vision-based techniques to detect and track the objects in motion, which serve as the predictor of the user’s future viewport of interest. In particular, we develop a set of algorithms to accommodate the various user movement patterns following a Tracking-Recovery-Update-Evaluation (T-R-U-E) workflow
Solution B: online CNN based viewport prediction (LiveDeep)
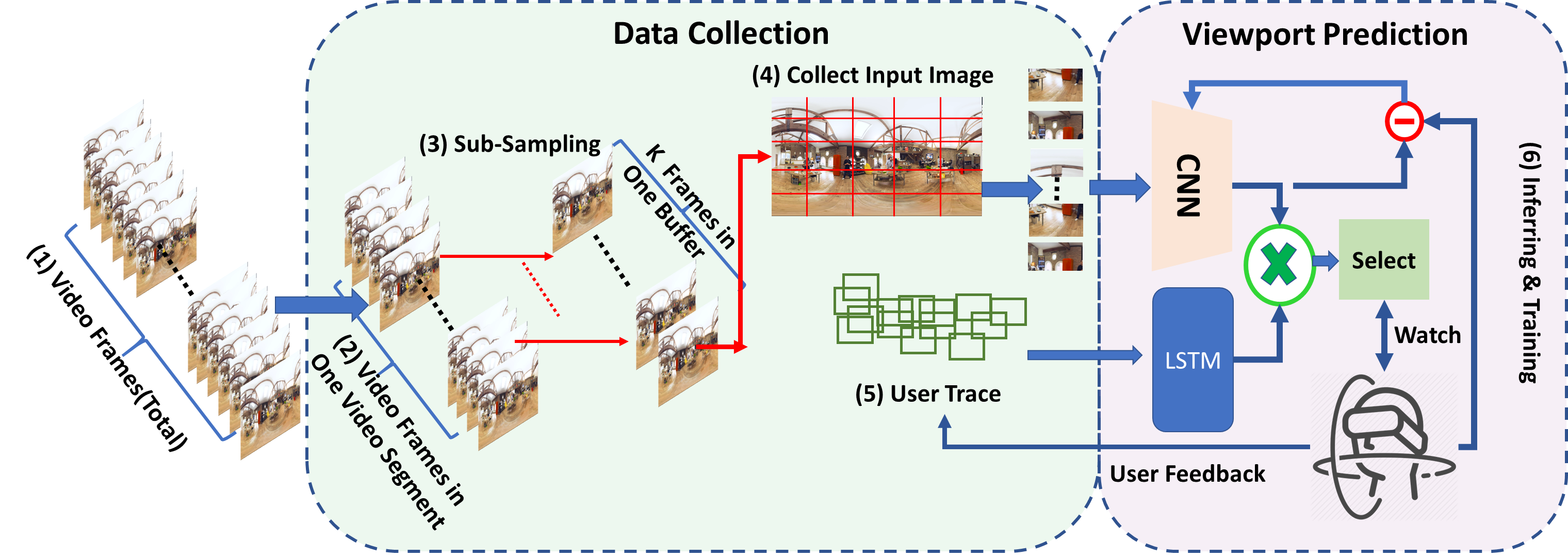
We explored the feasibility of using a single convolutional neural network (CNN) model for live viewport prediction and identified the limitations of the simple CNN structure. We further improve the performance of prediction by employing an alternate and hybrid deep learning approach involving both CNN and long short-term memory (LSTM) models.
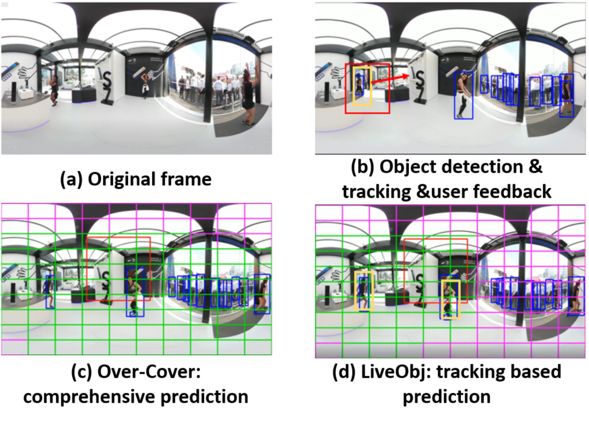
Solution C: Object detection based viewport prediction(LiveObj)
A computer vision based user study
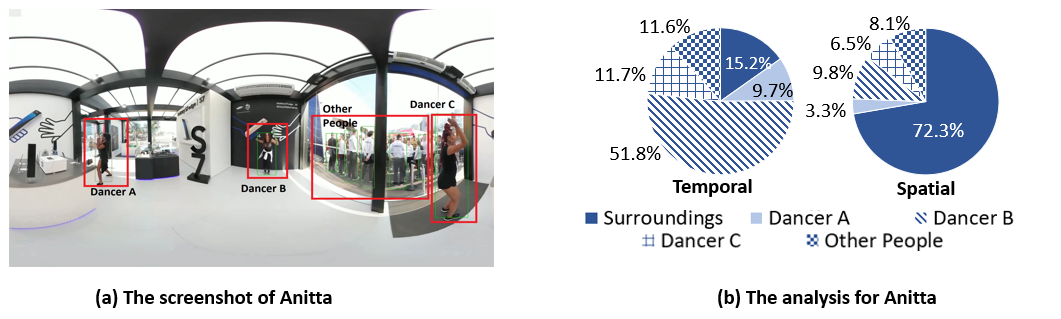
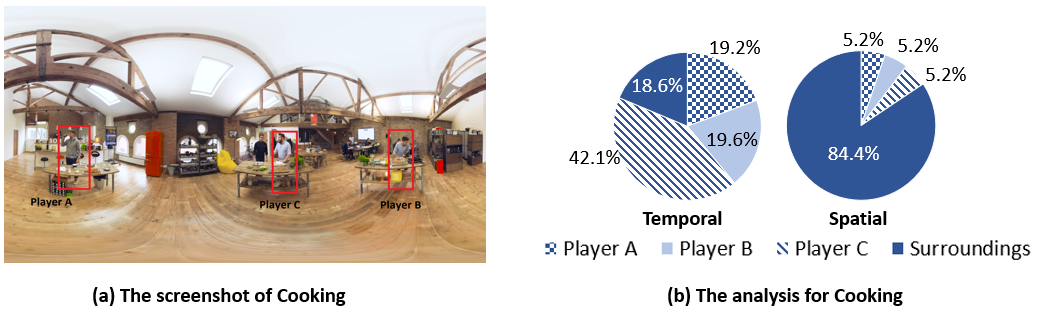
To analyze the user viewing behavior, we first deploy the YOLOv3object detection algorithm to detect the objects in each videoframe. Then, we implement the tracking algorithm from Collins etal. combined with location-based verification to match the objectsbetween frames. After that, we parse the user head movement dataand draw the conclusion on which objects the user has been watchingduring the live streaming session.
The analysis of the above two videos reveal an important observationthat the user’s viewport of interest (indicated by the temporal metric) isnot correlated with the size of the object (indicated by the spatial metric).Instead, the user’s viewport is heavily dependent upon the semanticsof the objects (i.e., the degree of importance or attractiveness) in thevideo, which validates our hypothesis that the users tend to watch themeaningful objects that they are interested in.

Error recovery strategies in selective streaming. (a) is the originalframe (red – predicted viewport, yellow – actual viewport). (b) showsthe user view with no recovery. (c) and (d) are the user views with adown-resolution rate of 20% and 60%, respectively
Security
VVSec: Securing Volumetric Video Streaming via Benign Use ofAdversarial Perturbation
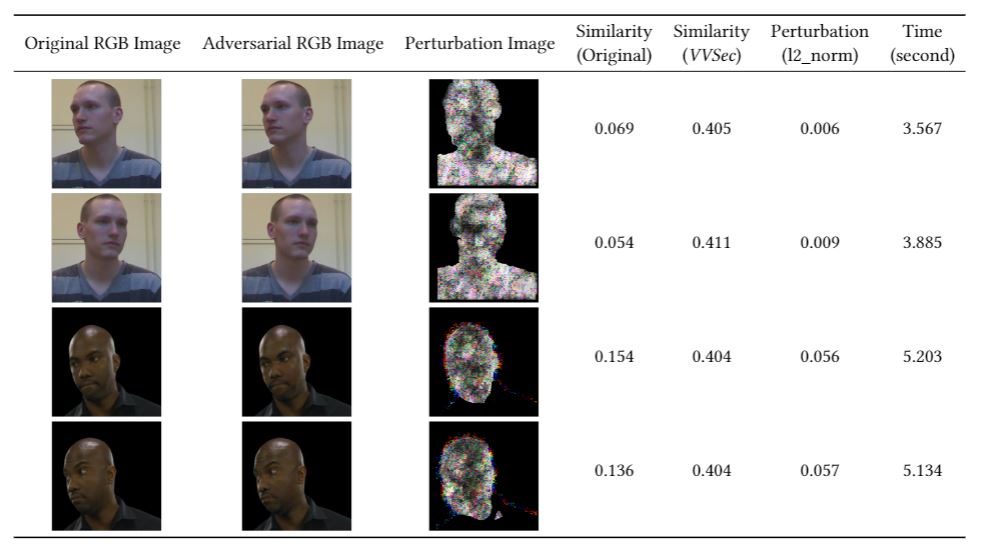
Inspired by the nature of the adversarial attacks, we propose anovel defense mechanisms,VVSec, to protect the confidentiality ofvolumetric video. In a nutshell,VVSecadds adversarial perturbationat the sender (i.e., Alice) side of the volumetric video streaming, sothat even if Malice could extract the RGB-D facial information inplaintext, it would fail to pass the face authentication due to theeffect of the "adversarial" perturbation on the deep neural network.On the other hand, the original functionality of volumetric stream-ing especially the perceivable quality of experience to human usersis unchanged, as ensured by the design principle of adversarialperturbations.
Runtime Fault Injection Detection for FPGA-based DNN Execution Using Siamese Path Verification
.png)
Cloud-Client system and how our SPV works
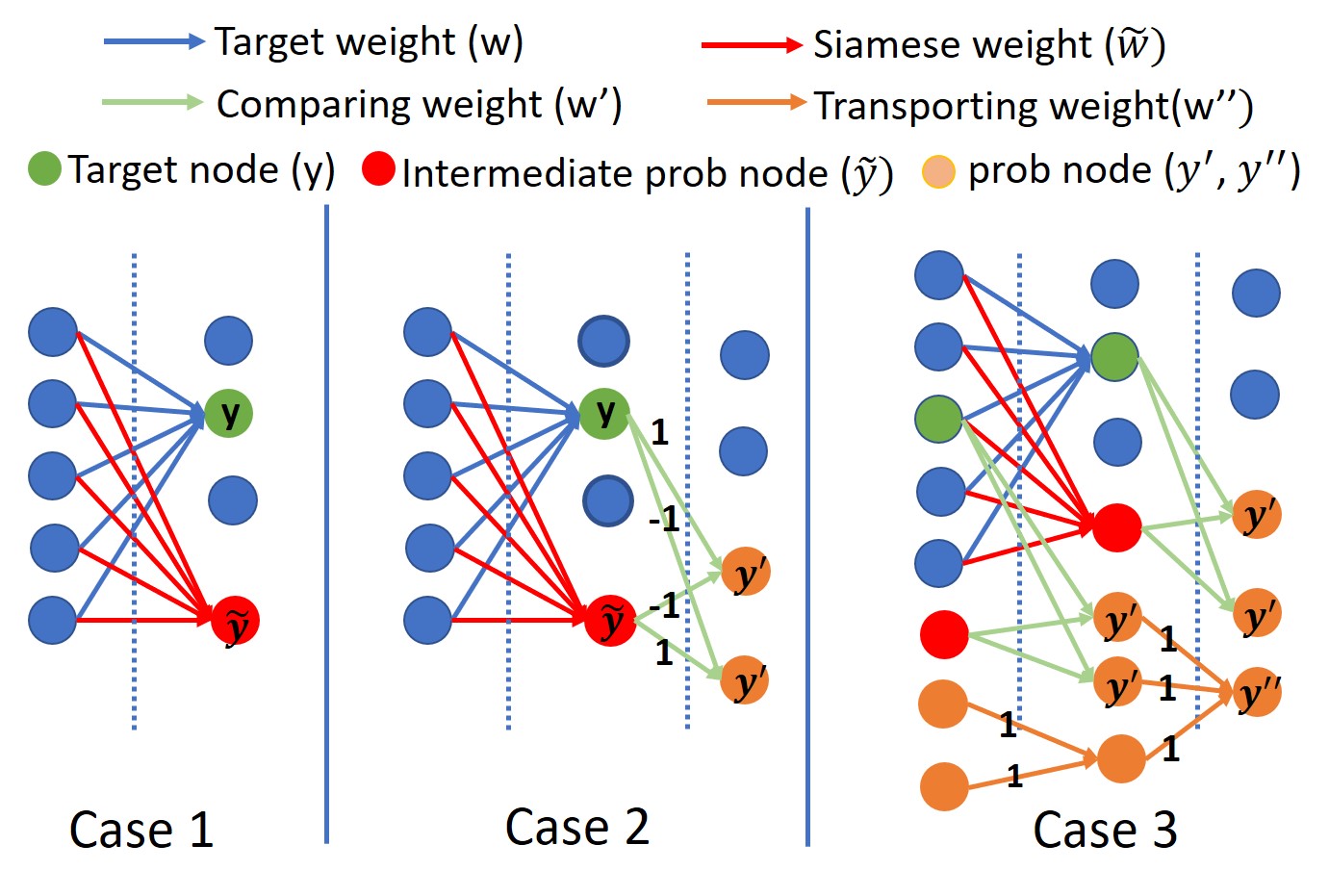
Siamese Path Verification framework in the DNN
Towards the Security of Motion Detection-based Video Surveillance on IoT Devices

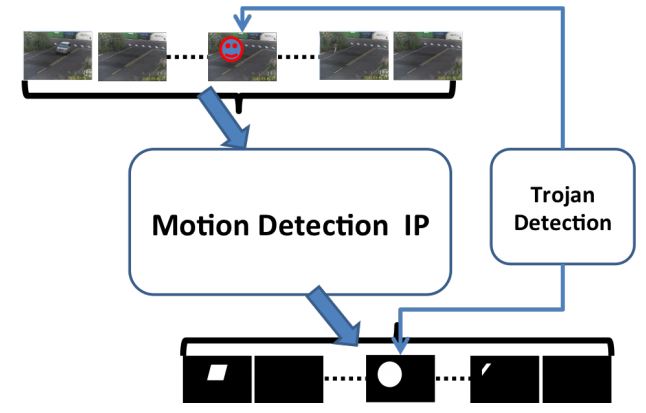
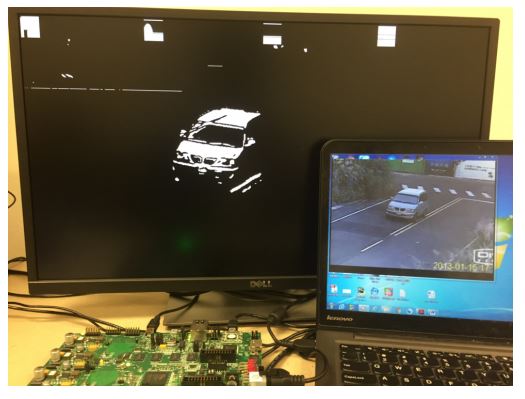
we implement a prototype system of a security sensitive surveillance camera, which has an on-device motion detection module to detect the objects in motion in the captured video in real time, as demonstrated in the above figure, which shows the hardware system setup using Xilinx Zynq-7000 ZC702 SoC. The SoC has a CPU component that contains two ARM cores and an FPGA component that contains a Xilinx FPGA board. We employ the CPU part on the board to provide basic interface to receive the video frames from the HDMI card, and we deploy a motion detection IP core in the FPGA part to conduct real time motion detection based on the received video frames. We then develop a proof-of-concept prototype demonstrating video replay attacks, in which the compromised surveillance device hides the chosen suspicious motion by overwriting the corresponding frames with pre-recorded normal frames under the control of the attacker.
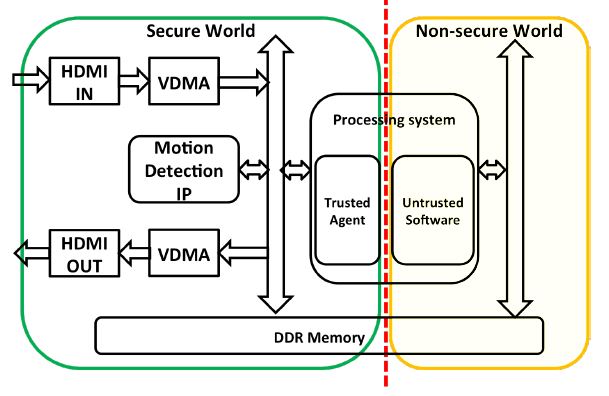
To address the security concerns, we develop a hardware-based IoT security framework that creates a trusted execution environment and physically isolates the security sensitive components, such as the motion detection module, from the rest of the system. We implement the security framework on an ARM system on chip (SoC).
Runtime verification based on proactive checking and approximating computing

To better illustrate the two CPU-FPGA threat models, we implement a prototype system of a security sensitive surveillance camera, which has an on-device motion detection module to detect the objects in motion in the captured video in real time, as demonstrated in the above figure, which shows the hardware system setup using Xilinx Zynq-7000 ZC702 SoC. The SoC has a CPU component that contains two ARM cores and an FPGA component that contains a Xilinx FPGA board. We employ the CPU part on the board to provide basic interface to receive the video frames from the HDMI card, and we deploy a motion detection IP core in the FPGA part to conduct real time motion detection based on the received video frames. As shown in (a) and (b), there is a remarkable white area to indicate the moving objects on the road. We further implement a threat model based on the prototype system. The outcome caused by the threat model is shown in (c), where the moving object is hidden in the background if there is no motion detected. The attack scenario is a “replay attack"
The inserted patterns will be captured by the motion detection module and labeled with white spots in the output frame, which can be as small as invisible to human. Then, the output verification in HISA can check the pixel values in the specific motion-inserted region to determine if they have been labeled in white.
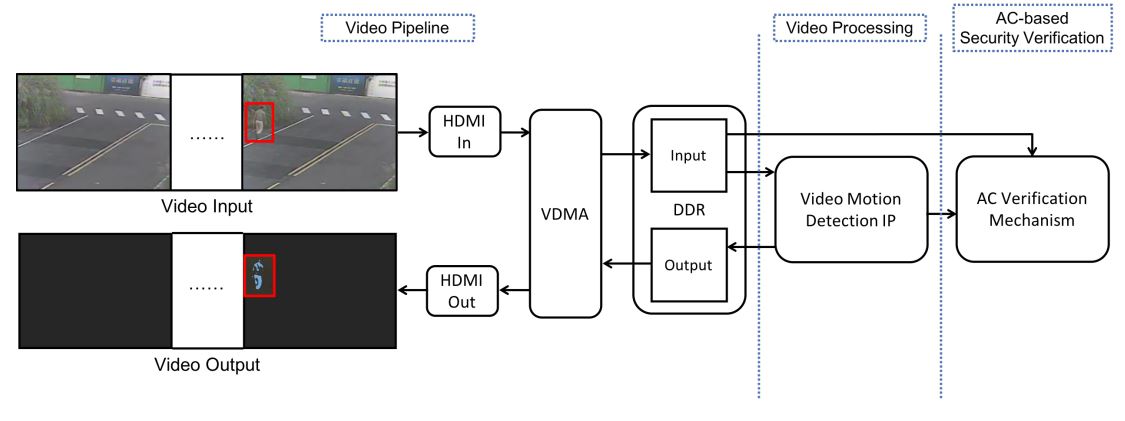
we develop and deploy the approximate computing-based verification framework to a CPU-FPGA prototype and conduct a comprehensive case study using a video motion detection application. The approximate computing algorithm employs two types of application-level approximations, namely spatial approximation and temporal approximation, to achieve the goals of runtime repeated execution and verification. Our empirical hardware evaluation on the Xilinx Zynq CPU-FPGA platform justifies the premium security and performance of the proposed approach. (SoC).
AI for next-generation wireless communication
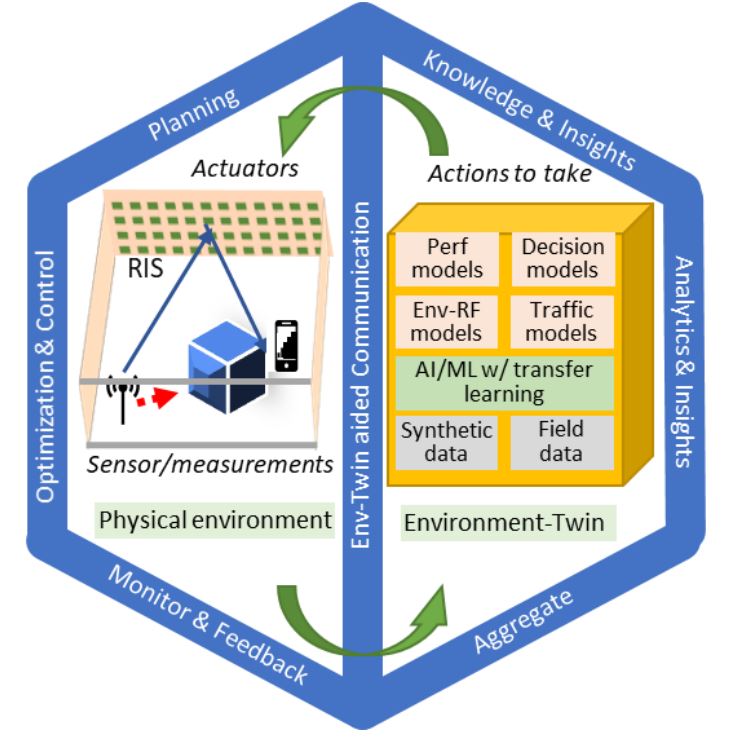
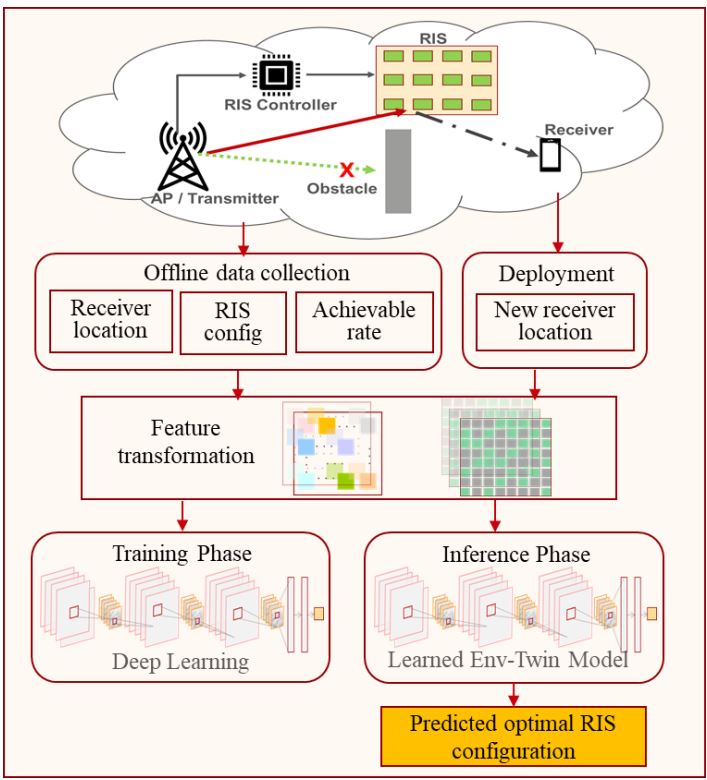
In this paper, we present a novel digital-twin framework for RIS-assisted wireless networks which we name it Environment-Twin (Env-Twin). The goal of the Env-Twin framework is to enable automation of optimal control at various granularities. In this paper, we present one example of the EnvTwin models to learn the mapping function between the RIS configuration with measured attributes for the receiver location, and the corresponding achievable rate in an RISassisted wireless network without involving explicit channel estimation or beam training overhead. Once learned, our EnvTwin model can be used to predict optimal RIS configuration for any new receiver locations in the same wireless network. We leveraged deep learning (DL) techniques to build our model and studied its performance and robustness.